SQL - RDBMS
관계형 데이터베이스
데이터는 테이블에 레코드로 저장되는데, 각 테이블마다 명확하게 정의된 구조가 있음.
따라서 정해진 구조에 맞는 레코드만 추가가 가능
데이터의 중복을 피하기 위해 관계를 이용. 하나의 테이블에서 중복없이 하나의 데이터만을 관리
장점
•
명확하게 정의된 스키마로 데이터의 무결성을 보장
•
각 데이터를 중복없이 한 번만 저장
단점
•
유연하지 않음. 한번 스키마를 설정하면 나중에 수정하기가 힘들다.
•
관계를 고려해야하기 때문에 조인문이 많은 복잡한 쿼리가 만들어질 수 있음
•
대체로 수직적 확장만 가능
⇒ 관계를 맺고있는 데이터가 자주 변경되는 애플리케이션 / 변경이 잘 되지 않고 명확한 스키마가 사용자와 데이터에게 중요한 경우
NoSQL
No SQL, Not Only SQL, Non-Relational Operational Database SQL
관계를 정의하지 않는다! 거대한 Map<>으로서 key-value 형식을 지원한다.
따로 구조가 정해져 있지 않음. 서로 다른 구조의 데이터를 같은 컬렉션에 추가가 가능하다.
관계형 데이터베이스 시스템의 주요 특성을 보장하는 ACID(Atomic, Consistency, Integrity, Duarabity) 특성을 제공하지 않는, 그렇지만 뛰어난 확장성이나 성능 등의 특성을 갖는 수많은 비관계형, 분산 데이터 베이스
읽기 작업보다는 쓰기작업이 빠름
RDBMS에 비해 쓰기와 읽기 성능이 빠름
•
nosql의 조인은?
컬렉션을 통해 데이터를 복제하여 각 컬렉션 일부분에 속하는 데이터를 정확하게 산출하도록 함
그러나 데이터가 중복되어 서로 영향을 줄 위험이 있다.
장점
•
유연함. 데이터의 구조를 언제든지 변경가능
•
애플리케이션이 필요로 하는 형식으로 저장이 가능하여 데이터를 읽어오는 속도가 빨라짐
단점
•
데이터 중복을 계속 업데이트해야함
•
데이터가 여러 컬렉션에 중복되어 있기 때문에 수정 시 모든 컬렉션에서 수행해야함
⇒ 조인을 잘 사용하지 않는 데이터 / 막대한 양의 데이터를 다뤄야하는 경우 / 읽기를 자주 하지만 데이터 변경은 자주 없는 경우
NoSQL 데이터 모델 분류
key에 저장되는 값에 따라 NoSQL을 분류한다.
1.
key-value database
redis(인메모리), oracle coherence 등
•
단순한 저장구조, 복잡한 조회연산을 지원하지 않음
•
고속 읽기와 쓰기에 최적화된 경우가 많음
•
메모리를 저장소로 쓰는 경우, 빠른 get과 put을 지원
•
value에는 또다른 key/value가 들어갈 수도 있음. 이를 column family라고함
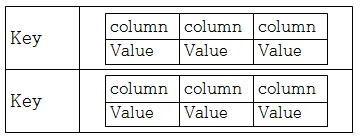
2.
Big table database (= ordered key-value, Wide Columnar Store)
Hbase, Cassandra 등
•
key-value와 데이터 저장방식은 동일하지만 내부적으로 key를 정렬해줌
⇒ 값을 날짜나 선착순으로 정렬해서 보여줄 때 유용
3.
Document database
mongoDB, CouchDB, Riak
•
key-value 의 확장된 형태로 value에 구조화된 문서데이터(XML, JSON, YAML 등) Document를 저장
•
복잡한 데이터 구조 표현가능
•
document id 또는 특정 속성값 기준으로 인덱스를 생성
⇒ sorting, join, grouping이 가능
4.
graph database
sones, allegroGraph, neo4j
•
node들과 relationship들로 구성된 개념으로, 모든 노드는 끊기지 않고 연결되어 있음
•
relationship은 direction, type, start node, end node에 대한 속성 등을 가짐
(보통 cost, weight 등의 양적인 속성들을 가짐)
CAP 이론
분산형 구조는 일관성, 가용성, 분산 허용의 3가지 특징을 가지고 있음.
CAP이론은 이 중 2가지만 만족할 수 있다는 이론
NoSQL은 대부분 이 cap이론을 따릅니다
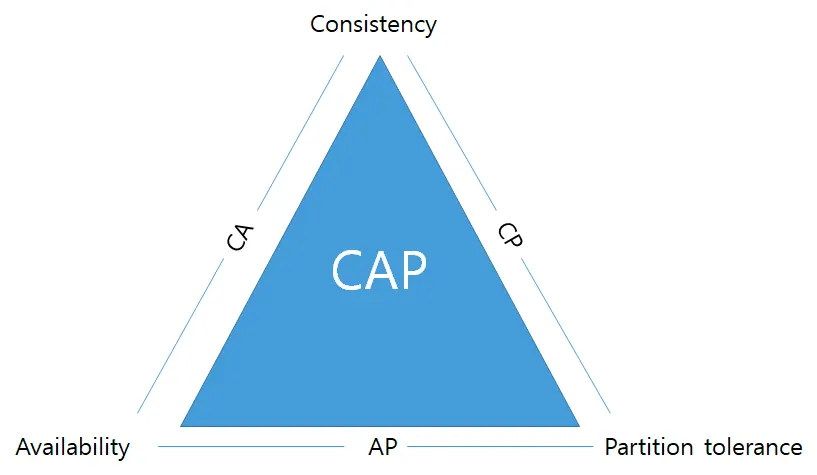
1. 일관성 Consistency
다중 클라이언트에서 같은 시간에 조회하는 데이터는 항상 동일한 데이터임을 보증하는 것을 의미
NoSQL은 데이터의 일관성이 느슨하게 처리되어(데이터의 변경을 시간의 흐름에 따라 여러 노드에 전파하는 것을 의미) 동일한 데이터가 나타나지 않을 수 있음.
NoSQL은 분산 노드 간의 데이터 동기화를 위해서 두 가지 방법을 사용
1.
동기식 방법
데이터의 저장 결과를 클라이언트로 응답하기 전에 모든 노드에 데이터를 저장
느린 응답시간을 보이지만 데이터의 정합성을 보장
2.
비동기식 방법
메모리나 임시 파일에 기록하고 클라이언트에 먼저 응답한 다음, 특정 이벤트 또는 프로세스를 사용하여 노드로 데이터를 동기화
빠른 응답시간 But 쓰기 노드에 장애가 발생했을 경우 데이터가 손실될 수 있음
2. 가용성 Availability
모든 클라이언트의 읽기와 쓰기 요청에 대하여 항상 응답이 가능해야 함
몇몇 노드 장애시에도 다른 노드들이 작동해야한다
3. 네트워크 분할 허용성 Partition tolerance
물리적 네트워크 분산 환경에서도 시스템은 잘 작동해야함
availability와 차이점은?
Availability는 특정 노드에 장애가 발생한 상황에 대한 것
분할 내성은 노드의 상태는 정상이지만 네트워크 문제로 서로간의 연결이 끊긴 상황에 대한 것
NoSQL은 CP, AP 형태를 가질 수 있음
데이터의 신뢰성 보다는 분산에 중점을 둔 방식 이라 약간의 데이터의 유실, 변형등이 발생할 수 있음
But, 빠르게 확장을 하여 대규모 데이터를 저장하고 핸들링 할 수 있는 구조를 갖출 수 있도록 함