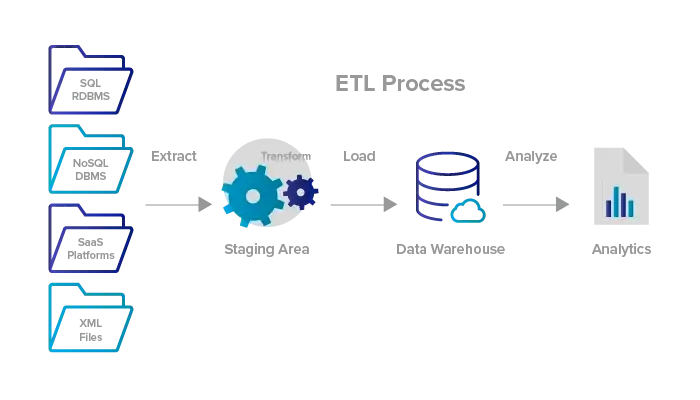
E T L ?
E/Extract (추출)
원본 데이터베이스 또는 데이터 소스에서 데이터를 가져오는 것
ETL을 사용할 경우 데이터가 임시 스테이징 영역으로 들어감
ELT를 사용할 경우 즉시 데이터가 Lake 스토리지 시스템으로 이동
T/Transform (변환)
데이터의 구조를 변경하는 프로세스
용도에 맞는 필터링, Reshaping, 정제 등의 단계를 통해 필요한 형태로 변환
L/Load (적재)
데이터를 스토리지에 저장하는 프로세스
ETL / ELT를 진행하는 이유?
데이터 사이언스 영역에서 필요함. 데이터를 담고있는 소스가 호환되는 형식으로 저장되어있지 않음.
따라서 데이터를 분석 가능한 데이터로 통합하기 전에 Raw 데이터를 정리하고, 많은 정보를 담을 수 있도록 변환해야함.
변환 후에 비로소 분석 도구나 플랫폼을 이용해 데이터가 담는 의미를 파악하고 통찰력을 얻을 수 있음
ETL
•
추출(E) → 변환(T) → 적재(L)
•
데이터 스테이징 단계가 소스와 데이터 웨어하우스 사이에 있음
•
데이터 웨어하우스에 로드하기 전, 중요 보안 데이터를 처리하여 개인정보 보호 규정을 준수 지원할 수 있음
•
정교한 데이터 변환 수행 가능
•
ELT보다 비용 효율적
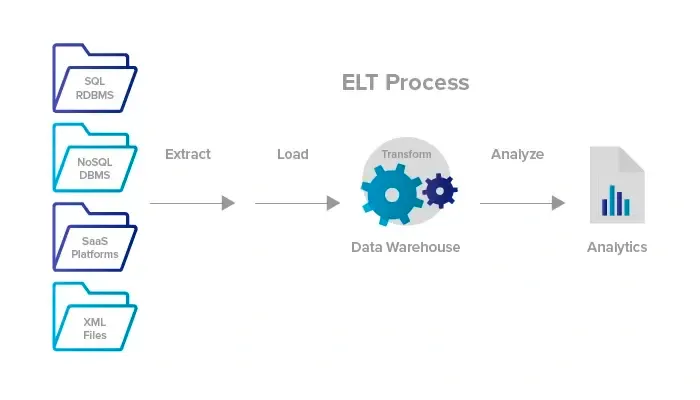
ELT
•
추출(E) → 적재(L) → 변환(T)
•
데이터 웨어하우스를 활용하여 기본 변환을 수행하며, 데이터 스테이징이 필요하지 않음
ETL?
OLAP 데이터 웨어하우스는 관계형 SQL 기반 데이터 구조를 지원함. NoSQL 기반의 데이터는 DW에 삽입되기 전 무조건 변환되어야 함.
→ 따라서 데이터 웨어하우스는 Load 단계 이전에 무조건 변환이 완료되어야하므로 ETL이 필요.
특징
•
워크플로우가 잘 정의되어 있어야 하며 연속적이고 지속적인 프로세스를 가짐
•
데이터 엔지니어 및 개발자의 상세 계획, 감독 및 코딩이 필요
•
최신 ETL 솔루션은 쉽고 빠름. ex) Xplentity
장점
•
데이터를 구조화/변환한 후 ETL을 통해 보다 효율적이며 안정적인 데이터 분석이 가능
•
데이터 웨어하우스에 넣기 전 변환하므로 보안 규정 위반 위험성을 줄여줌
•
ETL은 20년 넘는 기술스택을 쌓아왔으므로 잘 개발된 도구와 플랫폼이 많다.
ELT?
데이터를 먼저 추출 적재한 이후 변환을 하는 프로세스를 의미
데이터 웨어하우스에서 데이터 변환이 일어나므로 데이터 스테이징이 필요하지 않음
ELT는 클라우드 기반 데이터 웨어하우스 솔루션을 사용하여 정형, 비정형, 반정형 데이터 유형이 모든 데이터 타입을 활용할 수 있음
Data Lake(OLAP 데이터 웨어하우스와 달리 정형, 비정형 데이터 모두를 수용하는 특별한 저장소)에서 동작하므로 로드하기 전 데이터를 변환 할 필요가 없다. 모든 유형을 Raw 데이터 형태로 적재할 수 있다.
하지만 여전히 BI(Business intelligence) 플랫폼을 이용해 분석하기 위해서는 데이터 변환이 필요하므로 데이터 변환 과정은 데이터 레이크에 적재된 후에 수행된다.
특징
•
기술의 발전 덕분에 가능해진 고속 클라우드 서버 기반 프로세스
클라우드 기반 DW는 거의 무제한에 가까운 스토리지 기능과 확장 가능한 처리 능력을 제공
Ex) Amazon Redshift, Google BigQuery
•
모든 데이터를 수집 가능
•
필요한 데이터만 변환
•
ELT는 ETL보다 신뢰성이 낮다.
장점
•
새로운 비정형 데이터에 대한 유연성 및 저장 용이성
복잡한 ETL 프로세스 개발 필요 없음. 개발자와 BI 분석가가 새로운 정보를 처리하는데 소요되는 시간을 절약
•
빠름
•
유지보수 비용이 낮음 - 클라우드 기반으로 자동화된 솔루션을 활용
•
짧은 적재 시간 - 변환이 DW에 진입한 후에 발생하므로, 데이터를 최종 위치에 로드하는 데 걸리는 시간을 줄임
ETL? ELT?
ELT을 사용하는 게 좋을 때
•
방대한 양의 데이터를 보유했을 경우
•
가능한 한 빨리 모든 데이터를 한 곳에 보관해야 할 경우
•
데이터를 처리할 수 있는 리소스를 가지지 못했을 경우
Data Lake
데이터 웨어하우스 기반 파이프라인보다 훨씬 더 큰 개념
구조화된 데이터도 있지만, 비구조화된 데이터들이 존재
DW보다 용량도 크고 비용이 저렴해서 처음부터 지금까지 모든 데이터를 다 저장
→ 우선 데이터를 다 저장하고, 이 데이터를 어떻게 쓸지는 나중에 고민하자!
관리 방법
S3의 경우, 키를 기준으로 파티셔닝해서 데이터를 관리
데이터가 중복될 수도 있음
Data Warehouse
어느 정도 가치가 있고 구조화 된 데이터들이 모여있는 곳
공간에 제약이 있어서, 필요한 모든 데이터를 저장하지 않고 어느정도 최근 데이터만 저장
BI 툴이랑 연결해서 시각화하여 지표계산을 하는게 일반적
데이터레이크 중에서 의미가 있고 최근 데이터만 transform해서 dw에 load된다.
데이터레이크 데이터가 많아 일반적인 pandas로는 처리 어려움 → 분산 컴퓨팅 환경 (spark, redshift, spectrum, athena)를 통해서 data transform을 한다.